Kenning API¶
Deployment API overview¶
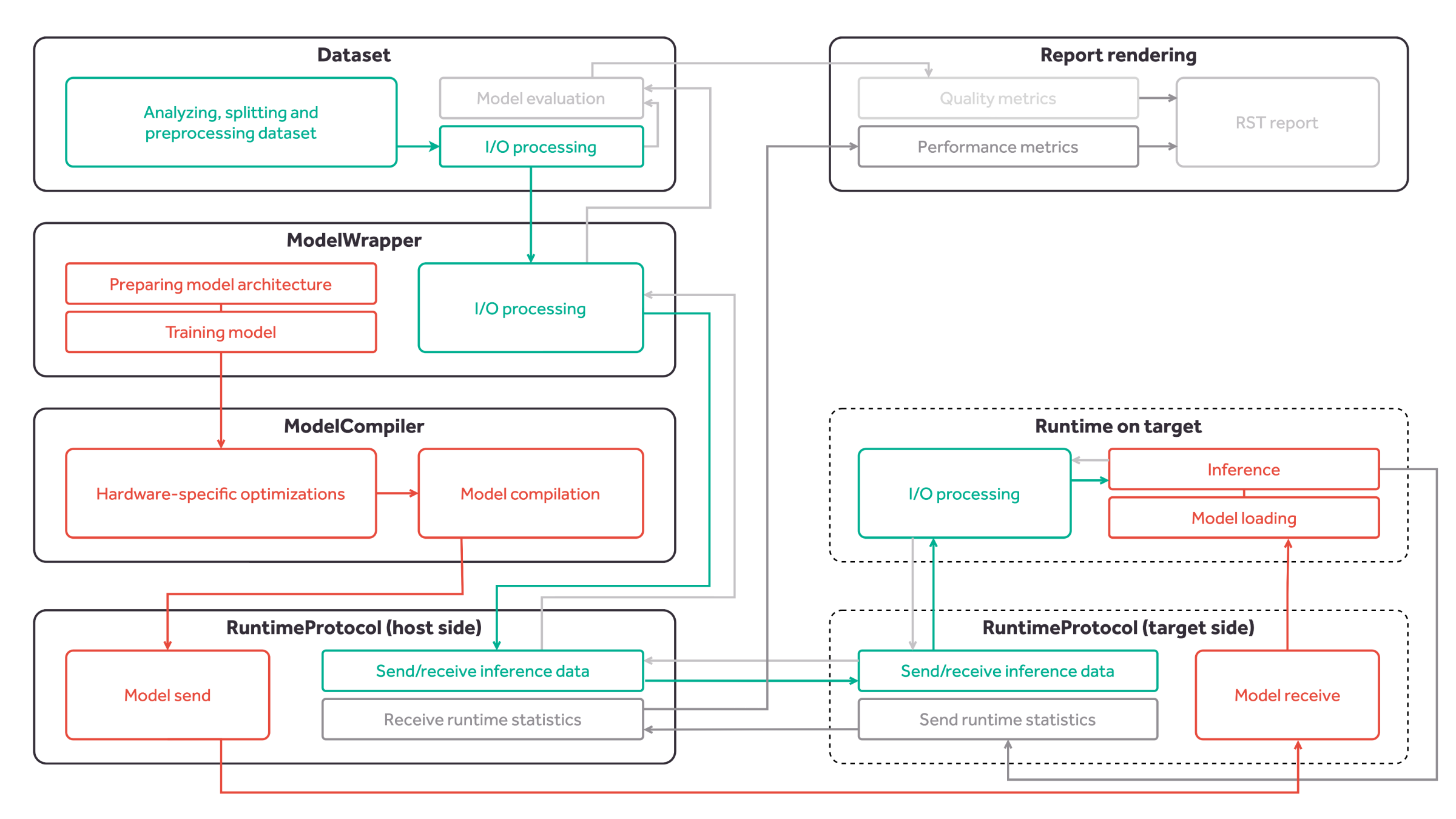
Figure 19 Kenning core classes and interactions between them. The green blocks represent the flow of input data passed to the model for inference. The orange blocks represent the flow of model deployment, from training to inference on target device. The grey blocks represent the inference results and metrics flow.¶
Kenning provides:
a Dataset class - performs dataset download, preparation, input preprocessing, output postprocessing and model evaluation,
a ModelWrapper class - trains the model, prepares the model, performs model-specific input preprocessing and output postprocessing, runs inference on host using a native framework,
a Optimizer class - optimizes and compiles the model,
a Runtime class - loads the model, performs inference on compiled model, runs target-specific processing of inputs and outputs, and runs performance benchmarks,
a Protocol class - implements the communication protocol between the host and the target,
a DataConverter class - performs conversion of data between different formats used by surrounding blocks,
a DataProvider class - implements providing data for inference from such sources as camera, TCP connection, or others,
a OutputCollector class - implements parsing and utilizing data coming from inference (such as displaying visualizations or sending results via TCP),
a ModelConverter class - converts model from one format to another.
Model processing¶
The orange blocks and arrows in Figure 19 represent a model’s life cycle:
the model is designed, trained, evaluated and improved - the training is implemented in the ModelWrapper.
Note
This is an optional step - an already trained model can also be wrapped and used.
the model is passed to the Optimizer where it is optimized for given hardware and later compiled,
during inference testing, the model is sent to the target using Protocol,
the model is loaded on target side and used for inference using Runtime.
Once the development of the model is complete, the optimized and compiled model can be used directly on target device using Runtime.
I/O data flow¶
The data flow is represented in the Figure 19 with green blocks. The input data flow is depicted using green arrows, and the output data flow is depicted using grey arrows.
Firstly, the input and output data is loaded from dataset files and processed. Later, since every model has its specific input preprocessing and output postprocessing routines, the data is passed to the ModelWrapper methods in order to apply modifications. During inference testing, the data is sent to and from the target using Protocol.
Lastly, since Runtimes also have their specific representations of data, proper I/O processing is applied.
Data flow reporting¶
Report rendering requires performance metrics and quality metrics. The flow for this is presented with grey lines and blocks in Figure 19.
On target side, performance metrics are computed and sent back to the host using the Protocol, and later passed to report rendering. After the output data goes through processing in the Runtime and ModelWrapper, it is compared to the ground truth in the Dataset during model evaluation. In the end, the results of model evaluation are passed to report rendering.
The final report is generated as an RST file containing figures, as can be observed in the Sample autogenerated report.
KenningFlow¶
kenning.core.flow.KenningFlow class allows for creation and execution of arbitrary flows built of runners.
It is responsible for validating all runners provided in a config file and their IO compatibility.
- class kenning.core.flow.KenningFlow(runners: list[Runner])¶
Bases:
objectAllows for creation of custom flows using Kenning core classes.
KenningFlow class creates and executes customized flows consisting of the runners implemented based on kenning.core classes, such as DatasetProvider, ModelRunner, OutputCollector. Designed flows may be formed into non-linear, graph-like structures.
The flow may be defined either directly via dictionaries or in a predefined JSON format.
The JSON format must follow well defined structure. Each runner should consist of following entries:
type - Type of a Kenning class to use for this module parameters - Inner parameters of chosen class inputs - Optional, set of pairs (local name, global name) outputs - Optional, set of pairs (local name, global name)
All global names (inputs and outputs) must be unique. All local names are predefined for each class. All variables used as input to a runner must be defined as a output of a runner that is placed before that runner.
- classmethod form_parameterschema() dict¶
Creates schema for the KenningFlow class.
- classmethod from_json(runners_specifications: list[dict[str, Any]]) KenningFlow¶
Constructor wrapper that takes the parameters from json dict.
This function checks if the given dictionary is valid according to the json schema defined in
form_parameterschema. If it is then it parses json and invokes the constructor.- Parameters:¶
- runners_specifications : List[Dict[str, Any]]¶
List of runners that creates the flow.
- Returns:¶
Object of class KenningFlow.
- Return type:¶
- Raises:¶
jsonschema.ValidationError – Raised for invalid JSON description
Exception – Raised for undefined and redefined variables, depending on context
- run()¶
Main process function. Repeatedly runs constructed graph in a loop.
- run_single_step()¶
Runs flow one time.
Runner¶
kenning.core.runner.Runner - based classes are responsible for executing various operation in KenningFlow (i.e. data providing, model execution, data visualization).
The available runner implementations are:
DataProvider - base class for data providing,
ModelRuntimeRunner - for running model inference,
OutputCollector - for processing model output.
- class kenning.core.runner.Runner(inputs_sources: dict[str, tuple[int, str]], inputs_specs: dict[str, dict], outputs: dict[str, str])¶
Bases:
IOInterface,ArgumentsHandler,ABCRepresents an operation block in Kenning Flow.
- cleanup()¶
Method that cleans resources after Runner is no longer needed.
- classmethod from_argparse(args: Namespace, inputs_sources: dict[str, tuple[int, str]], inputs_specs: dict[str, dict], outputs: dict[str, str]) Runner¶
Constructor wrapper that takes the parameters from argparse args.
This method takes the arguments created in form_argparse and uses them to create the object.
- classmethod from_json(json_dict: dict, inputs_sources: dict[str, tuple[int, str]], inputs_specs: dict[str, dict], outputs: dict[str, str]) Runner¶
Constructor wrapper that takes the parameters from json dict.
This function checks if the given dictionary is valid according to the json schema defined. If it is then it invokes the constructor.
Dataset¶
kennning.core.dataset.Dataset - based classes are responsible for:
dataset preparation, including download routines (use the
--download-datasetflag to download the dataset data),input preprocessing into a format expected by most models for a given task,
output postprocessing for the evaluation process,
model evaluation based on its predictions,
sample subdivision into training and validation datasets.
The Dataset objects are used by:
ModelWrapper - for training purposes and model evaluation,
Optimizer - can be used e.g. for extracting a calibration dataset for quantization purposes,
Runtime - for model evaluation on target hardware.
The available dataset implementations are included in the kenning.datasets submodule.
Example implementations:
PetDataset for classification,
OpenImagesDatasetV6 for object detection,
-
class kenning.core.dataset.Dataset(root: Path, batch_size: int =
1, download_dataset: bool =True, force_download_dataset: bool =False, external_calibration_dataset: Path | None =None, split_fraction_test: float =0.2, split_fraction_val: float | None =None, split_seed: int =1234, dataset_percentage: float =1, shuffle_data: bool =True)¶ Bases:
ArgumentsHandler,ABCWraps the datasets for training, evaluation and optimization.
This class provides an API for datasets used by models, compilers (i.e. for calibration) and benchmarking scripts.
Each Dataset object should implement methods for:
processing inputs and outputs from dataset files,
downloading the dataset,
evaluating the model based on dataset’s inputs and outputs.
The Dataset object provides routines for iterating over dataset samples with configured batch size, splitting the dataset into subsets and extracting loaded data from dataset files for training purposes.
- dataXtrain¶
dataX subset representing a training set. Available after executing train_test_split_representations, otherwise empty.
- Type:¶
List[Any]
- dataYtrain¶
dataY subset representing a training set. Available after executing train_test_split_representations, otherwise empty.
- Type:¶
List[Any]
- dataXtest¶
dataX subset representing a testing set. Available after executing train_test_split_representations, otherwise empty.
- Type:¶
List[Any]
- dataYtest¶
dataY subset representing a testing set. Available after executing train_test_split_representations, otherwise empty.
- Type:¶
List[Any]
- dataXval¶
Optional dataX subset representing a validation set. Available after executing train_test_split_representations, otherwise empty.
- Type:¶
List[Any]
- dataYval¶
Optional dataY subset representing a validation set. Available after executing train_test_split_representations, otherwise empty.
- Type:¶
List[Any]
-
calibration_dataset_generator(percentage: float =
0.25, seed: int | None =None) Generator[list[Any], None, None]¶ Creates generator for the calibration data.
- abstractmethod download_dataset_fun()¶
Downloads the dataset to the root directory defined in the constructor.
- abstractmethod evaluate(predictions: list, truth: list) Measurements¶
Evaluates the model based on the predictions.
The method should compute various quality metrics fitting for the problem the model solves - i.e. for classification it may be accuracy, precision, G-mean, for detection it may be IoU and mAP.
The evaluation results should be returned in a form of Measurements object.
- classmethod from_argparse(args: Namespace) Dataset¶
Constructor wrapper that takes the parameters from argparse args.
This method takes the arguments created in
form_argparseand uses them to create the object.
- classmethod from_json(json_dict: dict) Dataset¶
Constructor wrapper that takes the parameters from json dict.
This function checks if the given dictionary is valid according to the
arguments_structuredefined. If it is then it invokes the constructor.
- abstractmethod get_class_names() list[str]¶
Returns list of class names in order of their IDs.
- get_data() tuple[list, list]¶
Returns the tuple of all inputs and outputs for the dataset.
Warning
It loads all entries with prepare_input_samples and prepare_output_samples to the memory - for large datasets it may result in filling the whole memory.
- get_data_unloaded() tuple[list, list]¶
Returns the input and output representations before loading.
The representations can be opened using prepare_input_samples and prepare_output_samples.
- abstractmethod get_input_mean_std() tuple[Any, Any]¶
Returns mean and std values for input tensors.
The mean and std values returned here should be computed using
compute_input_mean_stdmethod.
- iter_test() DatasetIterator¶
Iterates over test data obtained from split.
- iter_train() DatasetIterator¶
Iterates over train data obtained from split.
- iter_val() DatasetIterator¶
Iterates over validation data obtained from split.
- abstractmethod prepare()¶
Prepares dataX and dataY attributes based on the dataset contents.
This can i.e. store file paths in dataX and classes in dataY that will be later loaded using prepare_input_samples and prepare_output_samples.
-
prepare_external_calibration_dataset(percentage: float =
0.25, seed: int =12345) list[Path]¶ Prepares the data for external calibration dataset.
This method is supposed to scan external_calibration_dataset directory and prepares the list of entries that are suitable for the prepare_input_samples method.
This method is called by the
calibration_dataset_generatormethod to get the data for calibration when external_calibration_dataset is provided.By default, this method scans for all files in the directory and returns the list of those files.
- prepare_input_samples(samples: list) list¶
Prepares input samples, i.e. load images from files, converts them.
By default the method returns data as is - without any conversions. Since the input samples can be large, it does not make sense to load all data to the memory - this method handles loading data for a given data batch.
- prepare_output_samples(samples: list) list¶
Prepares output samples.
By default the method returns data as is. It can be used i.e. to create the one-hot output vector with class association based on a given sample.
- save_dataset_checksum()¶
Writes dataset checksum to file.
- set_batch_size(batch_size: int)¶
Sets the batch size of the data in the iterator batches.
- test_subset_len() int | None¶
Returns the length of a single batch from the training set.
- train_subset_len() int | None¶
Returns the length of a single batch from the training set.
-
train_test_split_representations(test_fraction: float | None =
None, val_fraction: float | None =None, seed: int | None =None, stratify: bool =True, append_index: bool =False) tuple[list, ...]¶ Splits the data representations into train dataset and test dataset.
- Parameters:¶
- test_fraction : Optional[float]¶
The fraction of data to leave for model testing.
- val_fraction : Optional[float]¶
The fraction of data to leave for model validation.
- seed : Optional[int]¶
The seed for random state.
- stratify : bool¶
Whether to stratify the split.
- append_index : bool¶
Whether to return the indices of the split. If True, the returned tuple will have indices appended at the end. For example, if the split is (X_train, X_test, y_train, y_test), the returned tuple will be (X_train, X_test, y_train, y_test, train_indices, test_indices).
- Returns:¶
Split data into train, test and optionally validation subsets.
- Return type:¶
Tuple[List, …]
- val_subset_len() int | None¶
Returns the length of a single batch from the training set.
ModelWrapper¶
kenning.core.model.ModelWrapper base class requires implementing methods for:
model preparation,
model saving and loading,
model saving to the ONNX format,
model-specific preprocessing of inputs and postprocessing of outputs, if necessary,
model inference,
providing metadata (framework name and version),
model training,
input format specification,
conversion of model inputs and outputs to bytes for the
kenning.core.protocol.Protocolobjects.
The ModelWrapper provides methods for running inference in a loop for data from a dataset and measuring the model’s quality and inference performance.
The kenning.modelwrappers.frameworks submodule contains framework-wise implementations of the ModelWrapper class - they implement all methods common for given frameworks regardless of the model used.
For the Pet Dataset wrapper object, there is an example classifier implemented in TensorFlow 2.x called TensorFlowPetDatasetMobileNetV2 <https://github.com/antmicro/kenning/blob/main/kenning/modelwrappers/classification/tensorflow_pet_dataset.py>_.
Model wrapper examples:
PyTorchWrapper and TensorFlowWrapper implement common methods for all PyTorch and TensorFlow framework models,
PyTorchPetDatasetMobileNetV2 wraps the MobileNetV2 model for Pet classification implemented in PyTorch,
TensorFlowDatasetMobileNetV2 wraps the MobileNetV2 model for Pet classification implemented in TensorFlow,
TVMDarknetCOCOYOLOV3 wraps the YOLOv3 model for COCO object detection implemented in Darknet (without training and inference methods).
-
class kenning.core.model.ModelWrapper(model_path: Path | ResourceURI, dataset: Dataset | None, from_file: bool =
True, model_name: str | None =None)¶ Bases:
IOInterface,ArgumentsHandler,ABCWraps the given model.
- abstractmethod convert_input_to_bytes(inputdata: Any) bytes¶
Converts the input returned by the
preprocess_inputmethod to bytes.
- abstractmethod convert_output_from_bytes(outputdata: bytes) list[Any]¶
Converts bytes array to the model output format.
The converted output should be compatible with
postprocess_outputsmethod.
- abstractmethod classmethod derive_io_spec_from_json_params(json_dict: dict) dict[str, list[dict]]¶
Creates IO specification by deriving parameters from parsed JSON dictionary. The resulting IO specification may differ from the results of get_io_specification, information that couldn’t be retrieved from JSON parameters are absent from final IO spec or are filled with general value (example: ‘-1’ for unknown dimension shape).
-
classmethod from_argparse(dataset: Dataset | None, args: Namespace, from_file: bool =
True) ModelWrapper¶ Constructor wrapper that takes the parameters from argparse args.
-
classmethod from_json(json_dict: dict, dataset: Dataset | None =
None, from_file: bool =True) ModelWrapper¶ Constructor wrapper that takes the parameters from json dict.
This function checks if the given dictionary is valid according to the
arguments_structuredefined. If it is then it invokes the constructor.
- abstractmethod classmethod get_framework() str¶
Returns name of the framework.
- abstractmethod classmethod get_framework_version() str¶
Returns the framework version.
- get_io_specification() dict[str, list[dict]]¶
Returns a saved dictionary with input and output keys that map to input and output specifications.
A single specification is a list of dictionaries with names, shapes and dtypes for each layer. The order of the dictionaries is assumed to be expected by the ModelWrapper.
It is later used in optimization and compilation steps.
- abstractmethod get_io_specification_from_model() dict[str, list[dict]]¶
Returns a new instance of dictionary with input and output keys that map to input and output specifications.
A single specification is a list of dictionaries with names, shapes and dtypes for each layer. The order of the dictionaries is assumed to be expected by the ModelWrapper.
It is later used in optimization and compilation steps.
It is used by get_io_specification function to get the specification and save it for later use.
- get_model_size() float¶
Returns the model size.
By default, the size of file with model is returned.
- abstractmethod classmethod get_output_formats() list[str]¶
Returns list of names of possible output formats.
- get_path() Path | ResourceURI¶
Returns path to the model in a form of a Path or ResourceURI object.
- abstractmethod load_model(model_path: Path | ResourceURI)¶
Loads the model from file.
- classmethod parse_io_specification_from_json(json_dict)¶
Return dictionary with ‘input’ and ‘output’ keys that will map to input and output specification of an object created by the argument json schema.
A single specification is a list of dictionaries with names, shapes and dtypes for each layer.
Since no object initialization is done for this method, some IO specification may be incomplete, this method fills in -1 in case the information is missing from the JSON dictionary.
- postprocess_outputs(y: list[Any]) list[Any]¶
Processes the outputs for a given model.
By default no action is taken, and the outputs are passed unmodified.
- abstractmethod prepare_model()¶
Downloads the model (if required) and loads it to the device.
Should be used whenever the model is actually required.
The prepare_model method should check model_prepared field to determine if the model is not already loaded.
It should also set model_prepared field to True once the model is prepared.
- preprocess_input(X: list[Any]) list[Any]¶
Preprocesses the inputs for a given model before inference.
By default no action is taken, and the inputs are passed unmodified.
- read_platform(platform: Platform)¶
Reads Platform data to configure model.
Platform-based entities come with lots of information on hardware architecture that can be used by the ModelWrapper class.
By default no data is read.
It is important to take into account that different Platform-based classes come with a different sets of attributes.
- abstractmethod run_inference(X: list[Any]) list[Any]¶
Runs inference for a given preprocessed input.
- abstractmethod save_model(model_path: Path | ResourceURI)¶
Saves the model to file.
- abstractmethod save_to_onnx(model_path: Path | ResourceURI)¶
Saves the model in the ONNX format.
- test_inference() Measurements¶
Runs the inference on test split of the dataset.
- abstractmethod train_model()¶
Trains the model with a given dataset.
This method should implement training routine for a given dataset and save a working model to a given path in a form of a single file.
The training should be performed with given batch size, learning rate, and number of epochs.
The model needs to be saved explicitly.
Optimizer¶
kenning.core.optimizer.Optimizer objects wrap the deep learning compilation process.
They can perform the model optimization (operation fusion, quantization) as well.
Kenning supports executing optimizations also on the target device.
To do so you can use location parameter which specifies where given Optimizer would be executed (either 'host' or 'target').
Example model optimizers:
TFLiteCompiler - wraps TensorFlow Lite compilation,
TVMCompiler - wraps TVM compilation.
-
class kenning.core.optimizer.Optimizer(dataset: Dataset | None, compiled_model_path: Path | ResourceURI, location: 'host' | 'target' =
'host', model_wrapper: ModelWrapper | None =None)¶ Bases:
ArgumentsHandler,ABCCompiles the given model to a different format or runtime.
-
abstractmethod compile(input_model_path: Path | ResourceURI, io_spec: dict[str, list[dict]] | None =
None, **kwargs: dict)¶ Compiles the given model to a target format.
The function compiles the model and saves it to the output file.
The model can be compiled to a binary, a different framework or a different programming language.
If io_spec is passed, then the function uses it during the compilation, otherwise load_io_specification is used to fetch the specification saved in input_model_path + .json.
The compiled model is saved to compiled_model_path and the specification is saved to compiled_model_path + .json
- Parameters:¶
- input_model_path : PathOrURI¶
Path to the input model.
- io_spec : Optional[Dict[str, List[Dict]]]¶
Dictionary that has input and output keys that contain list of dictionaries mapping (property name) -> (property value) for the layers.
- **kwargs : Dict
Additional keyword arguments used mainly by converters.
- classmethod from_argparse(dataset: Dataset | None, args: Namespace) Optimizer¶
Constructor wrapper that takes the parameters from argparse args.
-
classmethod from_json(json_dict: dict, dataset: Dataset | None =
None, model_wrapper: ModelWrapper | None =None) Optimizer¶ Constructor wrapper that takes the parameters from json dict.
This function checks if the given dictionary is valid according to the
arguments_structuredefined. If it is then it invokes the constructor.
- abstractmethod classmethod get_framework() str¶
Returns name of the framework.
- abstractmethod classmethod get_framework_version() str¶
Returns version of the framework.
- classmethod get_input_formats() list[str]¶
Returns list of names of possible input formats.
- get_input_type(model_path: Path | ResourceURI) str¶
Return input model type. If input type is set to “any”, then it is derived from model file extension.
- get_model_class() Any | None¶
Function that tries to deduce model class of model wrapper.
- get_optimized_model_size() float¶
Returns the optimized model size.
By default, the size of file with optimized model is returned.
- classmethod get_output_formats() list[str]¶
Returns list of names of possible output formats.
- static get_spec_path(model_path: Path | ResourceURI) Path | ResourceURI¶
Returns input/output specification path for the model saved in model_path. It concatenates model_path and .json.
- init()¶
Initializes optimizer, should be called before compilation.
- load_io_specification(model_path: Path | ResourceURI) dict[str, list[dict]] | None¶
Returns saved input and output specification of a model saved in model_path if there is one. Otherwise returns None.
- read_platform(platform: Platform)¶
Reads Platform data to configure optimization/compilation.
Platform-based entities come with lots of information on hardware architecture that can be used by the Optimizer class.
By default no data is read.
It is important to take into account that different Platform-based classes come with a different sets of attributes.
- run_compatibility_checks(platform: Platform, runtime: Runtime | None, input_model_path: Path | ResourceURI) bool¶
Runs preliminary compatibility checks.
Performs most basic initial checks of this optimizer in the final pipeline.
-
save_io_specification(input_model_path: Path | ResourceURI, io_spec: dict[str, list[dict]] | None =
None)¶ Internal function that saves input/output model specification which is used during both inference and compilation. If io_spec is None, the function uses specification of an input model stored in input_model_path + .json. If there is no specification stored in this path the function does not do anything.
The input/output specification is a list of dictionaries mapping properties names to their values. Legal properties names are dtype, prequantized_dtype, shape, name, scale, zero_point.
The order of the layers has to be preserved.
- set_compiled_model_path(compiled_model_path: Path)¶
Sets path for compiled model.
- compiled_model_pathPathOrURI
Path to be set.
-
abstractmethod compile(input_model_path: Path | ResourceURI, io_spec: dict[str, list[dict]] | None =
Runtime¶
The kenning.core.runtime.Runtime class provides interfaces for methods for running compiled models locally or remotely on a target device.
Runtimes are usually compiler-specific (frameworks for deep learning compilers provide runtime libraries to run compiled models on particular hardware).
The client (host) side of the Runtime class utilizes the methods from Dataset, ModelWrapper and Protocol classes to run inference on a target device.
The server (target) side of the Runtime class requires method implementation for:
loading a model delivered by the client,
preparing inputs delivered by the client,
running inference,
preparing outputs for delivery to the client,
(optionally) sending inference statistics.
Runtime examples:
TFLiteRuntime for models compiled with TensorFlow Lite,
TVMRuntime for models compiled with TVM.
-
class kenning.core.runtime.Runtime(disable_performance_measurements: bool =
False, batch_size: int =1)¶ Bases:
ArgumentsHandler,ABCRuntime object provides an API for testing inference on target devices.
- abstractmethod extract_output() list[Any]¶
Extracts and postprocesses the output of the model.
- classmethod from_argparse(args: Namespace) Runtime¶
Constructor wrapper that takes the parameters from argparse args.
- classmethod from_json(json_dict: dict) Runtime¶
Constructor wrapper that takes the parameters from json dict.
This function checks if the given dictionary is valid according to the
arguments_structuredefined. If it is then it invokes the constructor.
- static get_available_ram(platform: Platform) float | None¶
Gets size of the RAM (or other type of memory where the model will be stored) for the given platform.
- classmethod get_input_formats() list[str]¶
Returns list of names of possible input formats names.
- static get_io_spec_path(model_path: Path | ResourceURI) Path¶
Gets path to a input/output specification file which is model_path and .json concatenated.
-
infer(X: list[ndarray], model_wrapper: ModelWrapper, postprocess: bool =
True) list[Any]¶ Runs inference on single batch locally using a given runtime.
- inference_session_end()¶
Calling this function indicates that the inference session has ended.
This method should be called once all the inference data is sent to the server by the client.
This will stop performance tracking.
- inference_session_start()¶
Calling this function indicates that the client is connected.
This method should be called once the client has connected to a server.
This will enable performance tracking.
- abstractmethod load_input(input_data: list[Any]) bool¶
Loads and converts delivered data to the accelerator for inference.
This method is called when the input is received from the client. It is supposed to prepare input before running inference.
- load_input_from_bytes(input_data: bytes) bool¶
The method accepts input_data in bytes and loads it according to the input specification.
It creates np.ndarray for every input layer using the metadata in self.input_spec and quantizes the data if needed.
Some compilers can change the order of the layers. If that’s the case the method also reorders the layers to match the specification of the model.
- prepare_io_specification(input_data: bytes | None) bool¶
Receives the io_specification from the client in bytes and saves it for later use.
input_datastores the io_specification representation in bytes. Ifinput_datais None, the io_specification is extracted from another source (i.e. from existing file). If it can not be found in this path, io_specification is not loaded.When no specification file is found, the function returns False as some Runtimes may not need io_specification to run the inference.
- prepare_local() bool¶
Runs initialization for the local inference.
- abstractmethod prepare_model(input_data: bytes | None) bool¶
Receives the model to infer from the client in bytes.
The method should load bytes with the model, optionally save to file and allocate the model on target device for inference.
input_datastores the model representation in bytes. Ifinput_datais None, the model is extracted from another source (i.e. from existing file or directory).
- preprocess_model_to_upload(path: Path | ResourceURI) Path | ResourceURI¶
The method preprocesses the model to be uploaded to the client and returns a new path to it.
The method is used to prepare the model to be sent to the client. It can be used to change the model representation, for example, to compress it.
- read_io_specification(io_spec: dict)¶
Saves input/output specification so that it can be used during the inference.
input_spec and output_spec are lists, where every element is a dictionary mapping (property name) -> (property value) for the layers.
The standard property names are: name, dtype and shape.
If the model is quantized it also has scale, zero_point and prequantized_dtype properties.
If the layers of the model are reorder it also has order property.
- read_platform(platform: Platform)¶
Reads Platform data to configure runtime.
Platform-based entities come with lots of information on hardware architecture that can be used by the Runtime class.
By default no data is read.
It is important to take into account that different Platform-based classes come with a different sets of attributes.
- abstractmethod run()¶
Runs inference on prepared input.
The input should be introduced in runtime’s model representation, or it should be delivered using a variable that was assigned in load_input method.
- Raises:¶
ModelNotLoadedError : – Raised if model is not loaded.
- run_compatibility_checks(platform: Platform, total_app_size: float) bool¶
Run initial compatibility checks.
Performs most basic initial checks of this runtime in the final pipeline.
Defined optionally, successful by default.
- upload_output(input_data: bytes) bytes¶
Returns the output to the client, in bytes.
The method converts the direct output from the model to bytes and returns them.
The wrapper later sends the data to the client.
- upload_stats(input_data: bytes) bytes¶
Returns statistics of inference passes to the client.
Default implementation converts collected metrics in MeasurementsCollector to JSON format and returns them for sending.
Platform¶
The kenning.core.platform.Platform classes represents the targeted environment providing additional context for optimization, compilation and evaluation of the model.
Platform examples:
-
class kenning.core.platform.Platform(name: str | None =
None, platforms_definitions: list[ResourceURI] | None =None)¶ Bases:
ArgumentsHandler,ABCWraps the platform that is being evaluated. This class provides methods to handle tested platform. The platform can be the device that Kenning is run on, a board running Kenning Zephyr Runtime or bare-metal IREE runtime or any remote or device running Kenning inference server.
-
deinit(measurements: Measurements | None =
None)¶ Deinitializes platform.
- Parameters:¶
- measurements : Optional[Measurements]¶
Measurements to which platform metrics can be added to.
- inference_step_callback()¶
Callback that is run every inference step.
- init()¶
Initializes the platform.
- post_init()¶
Called after the platform has been successfully setup, for cleanup or any other additional actions, that may be required by the platform.
- read_data_from_platforms_yaml()¶
Retrieves platform data from specified platform definition files.
-
deinit(measurements: Measurements | None =
AutoML¶
The AutoML API is combined from two different elements - AutoML model and AutoML flow mechanism.
AutoML examples:
AutoML model¶
The kenning.core.automl.AutoMLModel represents a model that can be used for AutoML flow, and defines additional methods for registering and managing parameters.
Moreover, the arguments_structure was extended with custom AutoML options, described in Defining arguments for core classes.
- class kenning.core.automl.AutoMLModel¶
Bases:
ArgumentsHandler,ABCBase class representing AutoML-compatible model.
Should be used together with kenning.core.model.ModelWrapper class.
- classmethod form_automl_schema() dict¶
Gathers AutoML schema based on arguments_structure of class and all parent.
- static update_automl_defaults(arg_structure: dict[str, dict], name: str)¶
Updates the default value of the AutoML parameter to make sure they fit into ranges.
AutoML flow mechanism¶
The kenning.core.automl.AutoML covers a standard AutoML flow: framework preparation, model searching and extraction to proper Kenning format.
-
class kenning.core.automl.AutoML(dataset: Dataset, platform: Platform, output_directory: Path, optimizers: list[Optimizer] =
[], runtime: Runtime | None =None, use_models: list[str | dict[str, tuple]] =[], time_limit: float =5.0, optimize_metric: str ='accuracy', n_best_models: int =5, application_size: float | None =None, skip_model_size_check: bool =False, callback_max_samples: int =30, seed: int =1234)¶ Bases:
ArgumentsHandler,ABCBase class describing AutoML flow: * preparing AutoML framework, * searching the best models, * generating Kenning configs based on found solutions.
- classmethod from_argparse(dataset: Dataset | None, platform: Platform | None, args: Namespace) AutoML¶
Constructor wrapper that takes the parameters from argparse args.
-
classmethod from_json(json_dict: dict, dataset: Dataset | None =
None, platform: Platform | None =None, optimizers: list[Optimizer] | None =None) AutoML¶ Constructor wrapper that takes the parameters from json dict.
This function checks if the given dictionary is valid according to the arguments_structure defined. If it is then it invokes the constructor.
- abstractmethod get_best_configs() Iterable[dict]¶
Extracts the best models and returns Kenning configuration for them.
- Yields:¶
Dict – Configuration for found models (from the best one).
- abstractmethod get_statistics() dict[str, int | float]¶
Returns statistic of the AutoML flow, like number of successful or crashed runs.
The created dictionary has to contain “general_info” - mapping of statisctics descriptions and values.
Optional fields: * “trained_model_metrics” - mapping of models to dictionaries
with datasets and metrics of trained models,
“training_data” - mapping of models to losses from different parts of training, containing dictionaries with timestamps and loss values (averaged from batch or whole epoch). Possible parts of training: “training”, “training_epoch”, “validation”, “validation_epoch”, “test” and “test_epoch”,
“training_start_time” - mapping of models to a list of times, marking the beginning of trainings,
“model_params” - mapping of models to dictionaries with parameters descriptions and values.
- abstractmethod prepare_framework()¶
Prepares AutoML framework.
- abstractmethod search()¶
Runs AutoML search.
Protocol¶
The kenning.core.protocol.Protocol is an abstract class that serves as a communication interface between the client (host) and the server (target platform).
For example it can be used to facilitate communication between Kenning client and Kenning Inference Server, but also between Kenning client and Kenning Zephyr Runtime Server.
It wraps the underlying communication logic, flow control and technology stack (for example KenningProtocol over TCP/IP) in abstract methods (to be overridden by its implementations), that can be called by client and server to communicate with each other.
Protocol implementations¶
kenning.core.protocol.Protocol implementations have to implement methods for:
initialization (separate for target and host) - initialize_server and initialize_client,
disconnecting (target and host) - disconnect,
uploading a runtime (host) - upload_runtime,
model input/output specification upload (host) - upload_io_specification,
model upload (host) - upload_model,
input data upload (host) - upload_input,
requesting input data processing (host) - request_processing,
downloading inference output (host) - download_output,
downloading inference statistics (host) - download_statistics,
uploading model optimizer configuration (host) - upload_optimizers,
requesting model optimization and downloading an optimized model (host) - request_optimization,
continuously receiving and processing log messages sent from the target (host) - listen_to_server_logs,
capturing and sending to the client log messages generated by the server (target) - start_sending_logs, stop_sending_logs
serving client requests (target) - serve (this method takes as arguments a number server callbacks, one for every type of client request)
If the implementation does not support one of the above methods, it must raise kenning.core.exceptions.NotSupportedError when called.
For detailed documentation of available kenning.core.protocol.Protocol implementations, see the Kenning Protocols chapter
Server callbacks¶
To use the Protocol on the server side, you need to implement a series of callback functions and pass them to the serve method:
-
kenning.core.protocol.Protocol.serve(self, upload_input_callback: Callable[[bytes], ServerStatus] | None =
None, upload_model_callback: Callable[[bytes], ServerStatus] | None =None, process_input_callback: Callable[[bytes], ServerStatus] | None =None, download_output_callback: Callable[[None], tuple[ServerStatus, bytes | None]] | None =None, download_stats_callback: Callable[[None], tuple[ServerStatus, bytes | None]] | None =None, upload_iospec_callback: Callable[[bytes], ServerStatus] | None =None, upload_optimizers_callback: Callable[[bytes], ServerStatus] | None =None, upload_unoptimized_model_callback: Callable[[bytes], ServerStatus] | None =None, download_optimized_model_callback: Callable[[None], tuple[ServerStatus, bytes | None]] | None =None, upload_runtime_callback: Callable[[bytes], ServerStatus] | None =None)¶ Waits for requests from the other device (the client) and calls appropriate callbacks. Some callbacks take bytes as arguments, all return ServerStatus and some also return bytes. These responses are then sent back to the client.
Callbacks are guaranteed to be executed in the order requests were sent in.
This method is non-blocking.
- Parameters:¶
- upload_input_callback : Optional[ServerUploadCallback]¶
Called, when the client uploads input (‘upload_input’ method below). Should upload model input into the runtime.
- upload_model_callback : Optional[ServerUploadCallback]¶
Called. when the client uploads optimized model (‘upload_model’ method below). It should load the model and start inference session.
- process_input_callback : Optional[ServerUploadCallback]¶
Called, when the client requests inference. Should return after inference is completed.
- download_output_callback : Optional[ServerDownloadCallback]¶
Called, when the client requests inference output, should return status of the server and the output.
- download_stats_callback : Optional[ServerDownloadCallback]¶
Called, when the client requests inference stats, should end the inference session and return status of the server and stats.
- upload_iospec_callback : Optional[ServerUploadCallback]¶
Called to upload model input/output specifications (iospec).
- upload_optimizers_callback : Optional[ServerUploadCallback]¶
Called to upload optimizer config (serialized JSON) - ‘upload_optimizers’ method call by the client.
- upload_unoptimized_model_callback : Optional[ServerUploadCallback]¶
Called to upload an unoptimized ML model, should save it.
- download_optimized_model_callback : Optional[ServerDownloadCallback]¶
Called, when client requests optimization of the model (uploaded with ‘upload_unoptimized_model_callback’). Should optimize the model and return it.
- upload_runtime_callback : Optional[ServerUploadCallback]¶
Called, when the client uploads runtime.
Implementations of the Protocol class should then implement the serve method to receive client requests (made for example by the client calling upload_input or request_optimization) and call appropriate callbacks (for example upload_input_callback).
Note that the request_optimization is a unique client request which should result in two server callbacks being called - first upload_unoptimized_model_callback and then download_optimized_model_callback.
There is no callback for the upload_runtime request, since this functionality is not supported by Kenning (only by certain other target platforms, like Kenning Zephyr Runtime).
Some callbacks (ServerUploadCallback) take bytes as an argument and return a ServerStatus object.
Other callbacks (ServerDownloadCallback) take no argument and return a tuple: (ServerStatus, bytes).
ServerStatus is a class meant to store the status of a server (target) and convey it to the client.
It stores information on what the server was last doing (through the ServerAction enum) and whether that action succeeded or failed, or whether it’s still ongoing.
Available values for ServerAction:
WAITING_FOR_CLIENTCLIENT_CONNECTEDUPLOADING_IOSPECUPLOADING_MODELUPLOADING_UNOPTIMIZED_MODELUPLOADING_INPUTPROCESSING_INPUTEXTRACTING_OUTPUTCOMPUTING_STATISTICSOPTIMIZING_MODELUPLOADING_OPTIMIZERSUPLOADING_RUNTIMEIDLE
-
class kenning.core.protocol.ServerStatus(last_action: ServerAction =
ServerAction.WAITING_FOR_CLIENT, success: bool =True)¶ Bases:
objectClass denoting status of an inference server (last executed action and information whether is succeeded or not).
Protocol methods¶
-
class kenning.core.protocol.Protocol(timeout: int =
-1)¶ Bases:
ArgumentsHandler,ABCThe interface for the communication protocol with the target devices.
The target device acts as a server in the communication.
The machine that runs the benchmark and collects the results is the client for the target device.
The inheriting classes for this class implement at least the client-side of the communication with the target device.
-
deduce_data_converter_from_io_spec(io_specification: dict | Path | None =
None) DataConverter¶ Function that reads model IO specification and then tries to deduce optimal data converter type.
- abstractmethod disconnect()¶
Ends connection with the other side.
- abstractmethod download_output() tuple[bool, Any | None]¶
Downloads the outputs from the target device.
Requests and downloads the latest inference output from the target device for quality measurements.
-
abstractmethod download_statistics(final: bool =
False) Measurements¶ Downloads inference statistics from the target device.
By default no statistics are gathered.
- classmethod from_argparse(args: Namespace) Protocol¶
Constructor wrapper that takes the parameters from argparse args.
- classmethod from_json(json_dict: dict) Protocol¶
Constructor wrapper that takes the parameters from json dict.
This function checks if the given dictionary is valid according to the
arguments_structuredefined. If it is then it invokes the constructor.
- abstractmethod initialize_client() bool¶
Initializes client side of the protocol.
The client side is supposed to run on host testing the target hardware.
The parameters for the client should be provided in the constructor.
-
abstractmethod initialize_server(client_connected_callback: Callable[[Any], None] | None =
None, client_disconnected_callback: Callable[[None], None] | None =None) bool¶ Initializes server side of the protocol.
The server side is supposed to run on target hardware.
The parameters for the server should be provided in the constructor.
- Parameters:¶
- client_connected_callback : Optional[Callable[Any, None]]¶
Called when a client connects to the server. Either IP address or another distinguishing characteristic of the client will be passed to the callback (depending on the underlying protocol).
- client_disconnected_callback : Optional[Callable[None, None]]¶
Called, when the current client disconnects from the server.
- Returns:¶
True if succeeded.
- Return type:¶
bool
- abstractmethod listen_to_server_logs()¶
Starts continuously receiving and printing logs sent by the server.
- abstractmethod listen_to_trace_data(tracedump_callback: Callable[[bytes], None])¶
Starts continuously receiving batches of trace data from server. Calls a callback function with each received batch.
- abstractmethod request_optimization(model_path: ~pathlib.Path | None, get_time_func: ~typing.Callable[[], float] = <built-in function perf_counter>) tuple[bool, bytes | None]¶
Request optimization of model.
- Parameters:¶
- model_path : Optional[Path]
Path to the model for optimization. If None, empty bytestream will be sent.
- get_time_func : Callable[[], float]
Function that returns current timestamp.
- Returns:¶
First element is equal to True if optimization finished successfully and the second element contains compiled model.
- Return type:¶
Tuple[bool, Optional[bytes]]
- abstractmethod request_processing(get_time_func: ~typing.Callable[[], float] = <built-in function perf_counter>) bool¶
Requests processing of input data and waits for acknowledgement.
This method triggers inference on target device and waits until the end of inference on target device is reached.
This method measures processing time on the target device from the level of the host.
Target may send its own measurements in the statistics.
-
abstractmethod serve(upload_input_callback: Callable[[bytes], ServerStatus] | None =
None, upload_model_callback: Callable[[bytes], ServerStatus] | None =None, process_input_callback: Callable[[bytes], ServerStatus] | None =None, download_output_callback: Callable[[None], tuple[ServerStatus, bytes | None]] | None =None, download_stats_callback: Callable[[None], tuple[ServerStatus, bytes | None]] | None =None, upload_iospec_callback: Callable[[bytes], ServerStatus] | None =None, upload_optimizers_callback: Callable[[bytes], ServerStatus] | None =None, upload_unoptimized_model_callback: Callable[[bytes], ServerStatus] | None =None, download_optimized_model_callback: Callable[[None], tuple[ServerStatus, bytes | None]] | None =None, upload_runtime_callback: Callable[[bytes], ServerStatus] | None =None)¶ Waits for requests from the other device (the client) and calls appropriate callbacks. Some callbacks take bytes as arguments, all return ServerStatus and some also return bytes. These responses are then sent back to the client.
Callbacks are guaranteed to be executed in the order requests were sent in.
This method is non-blocking.
- Parameters:¶
- upload_input_callback : Optional[ServerUploadCallback]¶
Called, when the client uploads input (‘upload_input’ method below). Should upload model input into the runtime.
- upload_model_callback : Optional[ServerUploadCallback]¶
Called. when the client uploads optimized model (‘upload_model’ method below). It should load the model and start inference session.
- process_input_callback : Optional[ServerUploadCallback]¶
Called, when the client requests inference. Should return after inference is completed.
- download_output_callback : Optional[ServerDownloadCallback]¶
Called, when the client requests inference output, should return status of the server and the output.
- download_stats_callback : Optional[ServerDownloadCallback]¶
Called, when the client requests inference stats, should end the inference session and return status of the server and stats.
- upload_iospec_callback : Optional[ServerUploadCallback]¶
Called to upload model input/output specifications (iospec).
- upload_optimizers_callback : Optional[ServerUploadCallback]¶
Called to upload optimizer config (serialized JSON) - ‘upload_optimizers’ method call by the client.
- upload_unoptimized_model_callback : Optional[ServerUploadCallback]¶
Called to upload an unoptimized ML model, should save it.
- download_optimized_model_callback : Optional[ServerDownloadCallback]¶
Called, when client requests optimization of the model (uploaded with ‘upload_unoptimized_model_callback’). Should optimize the model and return it.
- upload_runtime_callback : Optional[ServerUploadCallback]¶
Called, when the client uploads runtime.
- abstractmethod start_sending_logs()¶
Starts sending over the protocol all logs, except for the logs generated by the operation of sending logs itself (otherwise we would have an infinite logging recursion).
- abstractmethod stop_sending_logs()¶
Stops sending logs over the protocol.
- abstractmethod upload_input(data: Any) bool¶
Uploads input to the target device and waits for acknowledgement.
This method should wait until the target device confirms the data is delivered and preprocessed for inference.
- abstractmethod upload_io_specification(path: Path | None) bool¶
Uploads input/output specification to the target device.
This method takes the specification in a json format from the given Path and sends it to the target device.
This method should receive the status of uploading the data to the target.
- abstractmethod upload_model(path: Path | None) bool¶
Uploads the model to the target device.
This method takes the model from given Path and sends it to the target device.
This method should receive the status of uploading the model from the target.
- abstractmethod upload_optimizers(optimizers_cfg: dict[str, Any]) bool¶
Upload optimizers config to the target device.
-
deduce_data_converter_from_io_spec(io_specification: dict | Path | None =
DataConverter¶
kennning.core.dataconverter.DataConverter - based classes are responsible for:
converting data to the format expected by surrounding block,
converting data from the surrounding block format to one previous block excepts.
The DataConverter objects are used by PipelineRunner during inference.
The available implementations of dataconverter are included in the kenning.dataconverters submodule.
Example implementations:
ModelWrapperDataConverter implement conversions by utilizing the ModelWrapper classes,
ROS2DataConverter performs conversions by utilizing ROS2 action.
- class kenning.core.dataconverter.DataConverter¶
Bases:
ArgumentsHandler,ABCPerforms conversion of data between two surrounding blocks.
This class provides an API used by Runtimes during inference execution.
Each DataConverter should implement methods for:
converting data from dataset to the format used by the surrounding block.
converting data from format used by the surrounding block to the
inference output.
Measurements¶
The kenning.core.measurements module contains Measurements and MeasurementsCollector classes for collecting performance and quality metrics.
Measurements is a dict-like object that provides various methods for adding performance metrics, adding values for time series, and updating existing values.
The dictionary held by Measurements requires serializable data, since most scripts save performance results in JSON format for later report generation.
Module containing decorators for benchmark data gathering.
- class kenning.core.measurements.Measurements¶
Stores benchmark measurements for later processing.
This is a dict-like object that wraps all processing results for later report generation.
The dictionary in Measurements has measurement type as a key, and list of values for given measurement type.
There can be other values assigned to a given measurement type than list, but it requires explicit initialization.
- accumulate(measurementtype: str, valuetoadd: ~typing.Any, initvaluefunc: ~typing.Callable[[], ~typing.Any] = <function Measurements.<lambda>>)¶
Adds given value to a measurement.
This function adds given value (it can be integer, float, numpy array, or any type that implements iadd operator).
If it is the first assignment to a given measurement type, the first list element is initialized with the
initvaluefunc(function returns the initial value).- Parameters:¶
- measurementtype : str
The name of the measurement.
- valuetoadd : Any
New value to add to the measurement.
- initvaluefunc : Callable[[], Any]
The initial value of the measurement, default 0.
- add_measurement(measurementtype: str, value: ~typing.Any, initialvaluefunc: ~typing.Callable[[], ~typing.Any] = <function Measurements.<lambda>>)¶
Add new value to a given measurement type.
- Parameters:¶
- measurementtype : str
The measurement type to be updated.
- value : Any
The value to add.
- initialvaluefunc : Callable[[], Any]
The initial value for the measurement.
- clear()¶
Clears measurement data.
- copy()¶
Makes copy of measurements data.
- get_values(measurementtype: str) list¶
Returns list of values for a given measurement type.
- initialize_measurement(measurement_type: str, value: Any)¶
Sets the initial value for a given measurement type.
By default, the initial values for every measurement are empty lists. Lists are meant to collect time series data and other probed measurements for further analysis.
In case the data is collected in a different container, it should be configured explicitly.
- update_measurements(other: dict | Measurements)¶
Adds measurements of types given in the other object.
It requires another Measurements object, or a dictionary that has string keys and values that are lists of values. The lists from the other object are appended to the lists in this object.
- class kenning.core.measurements.MeasurementsCollector¶
It is a ‘static’ class collecting measurements from various sources.
- classmethod clear()¶
Clears measurement data.
- classmethod save_measurements(resultpath: Path)¶
Saves measurements to JSON file.
-
classmethod set_unoptimized(optimized_measurementspath: Path, unoptimized_measurementspath: Path, remove_unoptimized_measurementsfile: bool =
True)¶ Copies unoptimized model measurements to UNOPTIMIZED field of the optimized model measurements.
-
class kenning.core.measurements.SystemStatsCollector(prefix: str, step: float =
0.1)¶ It is a separate thread used for collecting system statistics.
It collects:
CPU utilization,
RAM utilization,
GPU utilization,
GPU Memory utilization.
It can be executed in parallel to another function to check its utilization of resources.
- get_measurements() Measurements¶
Returns measurements from the thread.
Collected measurements names are prefixed by the prefix given in the constructor.
The list of measurements:
<prefix>_cpus_percent: gives per-core CPU utilization (%),
<prefix>_mem_percent: gives overall memory usage (%),
<prefix>_gpu_utilization: gives overall GPU utilization (%),
<prefix>_gpu_mem_utilization: gives overall memory utilization (%),
<prefix>_timestamp: gives the timestamp of above measurements (ns).
- run()¶
Method representing the thread’s activity.
You may override this method in a subclass. The standard run() method invokes the callable object passed to the object’s constructor as the target argument, if any, with sequential and keyword arguments taken from the args and kwargs arguments, respectively.
-
kenning.core.measurements.systemstatsmeasurements(measurementname: str, step: float =
0.5) Callable¶ Decorator for measuring memory usage of the function.
Check SystemStatsCollector.get_measurements for list of delivered measurements.
- kenning.core.measurements.tagmeasurements(tagname: str) Callable¶
Decorator for adding tags for measurements and saving their timestamps.
- kenning.core.measurements.timemeasurements(measurementname: str, get_time_func: ~typing.Callable[[], float] = <built-in function perf_counter>) Callable¶
Decorator for measuring time of the function.
The duration is given in nanoseconds.
ONNXConversion¶
The ONNXConversion object contains methods for model conversion in various frameworks to ONNX and vice versa.
It also provides methods for testing the conversion process empirically on a list of deep learning models implemented in the tested frameworks.
- class kenning.core.onnxconversion.ONNXConversion(framework: str, version: str)¶
Bases:
ABCCreates ONNX conversion support matrix for given framework and models.
- add_entry(name: str, modelgenerator: Callable, **kwargs: dict[str, Any])¶
Adds new model for verification.
- Parameters:¶
- name : str¶
Full name of the model, should match the name of the same models in other framework’s implementations.
- modelgenerator : Callable¶
Function that generates the model for ONNX conversion in a given framework. The callable should accept no arguments.
- **kwargs : Dict[str, Any]
Additional arguments that are passed to ModelEntry object as parameters.
- check_conversions(modelsdir: Path) list[Support]¶
Runs ONNX conversion for every model entry in the list of models.
- abstractmethod onnx_export(modelentry: ModelEntry, exportpath: Path) SupportStatus¶
Virtual function for exporting the model to ONNX in a given framework.
This method needs to be implemented for a given framework in inheriting class.
- abstractmethod onnx_import(modelentry: ModelEntry, importpath: Path) SupportStatus¶
Virtual function for importing ONNX model to a given framework.
This method needs to be implemented for a given framework in inheriting class.
- abstractmethod prepare()¶
Virtual function for preparing the ONNX conversion test.
This method should add model entries using add_entry methods.
It is later called in the constructor to prepare the list of models to test.
DataProvider¶
The DataProvider classes are used during deployment to provide data for inference.
They can provide data from such sources as a camera, video files, microphone data or a TCP connection.
The available DataProvider implementations are included in the kenning.dataproviders submodule.
Example implementations:
CameraDataProvider for capturing frames from camera.
-
class kenning.core.dataprovider.DataProvider(inputs_sources: dict[str, tuple[int, str]] =
{}, inputs_specs: dict[str, dict] ={}, outputs: dict[str, str] ={})¶ Bases:
Runner,ABCA block that introduces data to Kenning flow.
- abstractmethod detach_from_source()¶
Detaches from the source during shutdown.
- abstractmethod fetch_input() Any¶
Gets the sample from device.
- prepare()¶
Prepares the source for data gathering depending on the source type.
This will for example initialize the camera and set the self.device to it.
OutputCollector¶
The OutputCollector classes are used during deployment for inference results receiving and processing.
They can display the results, send them, or store them in a file.
The available output collector implementations are included in the kenning.outputcollectors submodule.
Example implementations:
DetectionVisualizer for visualizing detection model outputs,
BaseRealTimeVisualizer base class for real time visualizers:
RealTimeDetectionVisualizer for visualizing detection model outputs,
RealTimeSegmentationVisualizer for visualizing segmentation model outputs,
RealTimeClassificationVisualizer for visualizing classification model outputs.
-
class kenning.core.outputcollector.OutputCollector(inputs_sources: dict[str, tuple[int, str]] =
{}, inputs_specs: dict[str, dict] ={}, outputs: dict[str, str] ={})¶ Bases:
Runner,ABCCollects outputs from models running in the Kenning flow.
It performs final processing of data running in the Kenning flow. It can be used i.e. to display predictions, save them to file or send to other application.
- abstractmethod detach_from_output()¶
Detaches from the output during shutdown.
- abstractmethod process_output(input_data: Any, output_data: Any)¶
Returns the inferred data back to the specific place/device/connection.
Eg. it can save a video file with bounding boxes on objects or stream it via a TCP connection, or just show it on screen.
ArgumentsHandler¶
The ArgumentsHandler class is responsible for concatenating arguments_structure and creating parsers for command line and JSON config arguments.
In order to make some class being able to be instantiated from command line arguments or JSON config it is required to inherit from this class or its child class and implement from_argparse or from_json methods as described in Defining arguments for core classes.
- class kenning.utils.args_manager.ArgumentsHandler¶
Bases:
ABCClass responsible for creating parsers for arguments from command line or json configs.
The child class should define its own arguments_structure and from_argparse/from_json methods so that it could be instantiated from command line arguments or json config.
-
classmethod form_argparse(args: Namespace, override_only: bool =
False) tuple[ArgumentParser, _ArgumentGroup | None]¶ Creates argparse parser based on arguments_structure of class and its all parent classes.
- classmethod form_parameterschema() dict¶
Creates parameter schema based on arguments_structure of class and its all parent classes.
- classmethod from_argparse(args: Namespace, **kwargs: dict[str, Any]) Any¶
Constructor wrapper that takes the parameters from argparse args.
-
classmethod form_argparse(args: Namespace, override_only: bool =
ResourceManager¶
The ResourceManager is a singleton class which handles local and remote files for Kenning, such as datasets or models.
It downloads missing files, provides paths to the available files, resolves custom URL schemes for and manages resource directories for Kenning, including cleanup.
- class kenning.utils.resource_manager.ResourceManager(*args, **kwargs)¶
Bases:
objectDownload and cache resources used by Kenning.
- add_custom_url_schemes(custom_url_schemes: dict[str, str | Callable | None])¶
Add user defined URL schemes.
- check_for_uri(uri: str) str | Path | None¶
A function that whether a input uri string is a valid supported URI string.
- clear_cache()¶
Remove all cached files.
-
get_resource(uri: str, output_path: Path | None =
None) Path¶ Retrieve file and return path to it.
If the uri points to remote resource, then it is downloaded (if not found in cache) and validated.
- list_cached_files() list[Path]¶
Return list with cached files.
- set_cache_dir(cache_dir_path: Path)¶
Set the cache directory path and creates it if not exists.
- set_max_cache_size(max_cache_size: int)¶
Set the max cache size.
- validate_resources_version()¶
Retrieve Kenning resources version and check if it is compatible with currently used Kenning.
ResourceURI¶
The ResourceURI class is a pathlib.Path-based object allowing the user to work with Kenning resources, both using regular paths and URI schemes supported by the ResourceManager.
- class kenning.utils.resource_manager.ResourceURI(uri_or_path: str | Path | ResourceURI)¶
Bases:
PathHandle access to resource used in Kenning.
- property origin : str¶
Returns the original string passed to the constructor.
- property parent : ResourceURI¶
Get parent of the URI.
- property uri : str | None¶
Get URI of the resource.
- with_name(name: str) ResourceURI¶
Return new URI with changed name.
- with_stem(stem: str) ResourceURI¶
Return new URI with changed stem.
ModelConverter¶
kenning.core.converter.ModelConverter objects allow conversion between deep learning frameworks (e.g. PyTorch, Keras, ONNX, TVM and more).
They allow alternative paths for optimizations, when Optimizer objects do not support current model format, or when direct optimization fails.
For conversion to be possible, a converter needs to implement to_<destination_format> method.
Example model converters:
OnnxConverter - wraps conversion from ONNX,
KerasConverter - wraps conversion from Keras.
- class kenning.core.converter.ModelConverter(source_model_path: Path | ResourceURI)¶
Bases:
ABCLoads or converts model to specific format.
-
to_ai8x(ai8x_model_path: Path, ai8x_tools: Ai8xTools, model: Any | None =
None, **kwargs) None¶ Converts model to ai8x format.
-
to_tflite(model: Any | None =
None, **kwargs) tf.lite.TFLiteConverter | tflite.Model.Model¶ Converts model to TensorFlowLite format.
-
to_ai8x(ai8x_model_path: Path, ai8x_tools: Ai8xTools, model: Any | None =