Structured pruning for PyTorch models¶
Structured pruning is of the methods for reducing model size, which removes the least contributing neurons, filters and/or convolution kernels.
In this example, we present scenarios for structured pruning of PyTorchPetDatasetMobileNetV2 using Neural Network Intelligence.
Setup¶
Install required dependencies:
pip install "kenning[nni,reports] @ git+https://github.com/antmicro/kenning.git"
Experiments¶
In order to compare with an original model, you need to execute a scenario:
{
"model_wrapper": {
"type": "kenning.modelwrappers.classification.pytorch_pet_dataset.PyTorchPetDatasetMobileNetV2",
"parameters": {
"model_path": "kenning:///models/classification/pytorch_pet_dataset_mobilenetv2_full_model.pth",
"model_name": "torch-native"
}
},
"dataset": {
"type": "kenning.datasets.pet_dataset.PetDataset",
"parameters": {
"dataset_root": "./build/PetDataset",
"image_memory_layout": "NCHW"
}
},
"optimizers": [],
"runtime": {
"type": "kenning.runtimes.pytorch.PyTorchRuntime",
"parameters": {
"save_model_path": "kenning:///models/classification/pytorch_pet_dataset_mobilenetv2_full_model.pth"
}
}
}
To run it, use this command:
kenning test \
--json-cfg mobilenetv2-pytorch.json \
--measurements build/torch.json
Kenning supports activation-based pruners.
You can choose a specific pruner with the pruner_type parameter:
apoz-ActivationAPoZRankPrunerbased on Average Percentage of Zeros in activations,mean_rank-ActivationMeanRankPrunerbased on a metric that calculates the smallest mean value of activations.
These activations are collected during dataset inference.
The number of samples collected for statistics can be modified with training_steps.
Moreover, pruning has two modes:
dependency_aware- makes pruner aware of dependencies for channels and groups.normal- dependencies are ignored.
You can also choose which activation the pruner will use - relu, relu6 or gelu.
Additional configuration can be specified in config_list which follows a format defined in the NNI specification.
When exclude_last_layer is positive, the optimizer will be configured to exclude the last layer from the pruning process, to prevent changing the size of the output.
Apart from that, confidence defines the coefficient for sparsity inference and batch size of the dummy input for the process.
When a GPU is available, it is used by default, but as pruning can be memory-consuming, the pruning_on_cuda option enables manual GPU usage configuration during the process.
Other arguments affect fine-tuning of the pruned model, e.g. criterion and optimizer accept paths to classes, respectively calculating a criterion and optimizing a neural network.
The number of finetuning_epochs, the finetuning_batch_size and finetuning_learning_rate can be modified.
{
"model_wrapper": {
"type": "kenning.modelwrappers.classification.pytorch_pet_dataset.PyTorchPetDatasetMobileNetV2",
"parameters": {
"model_path": "kenning:///models/classification/pytorch_pet_dataset_mobilenetv2_full_model.pth",
"model_name": "nni-pruning-0_05"
}
},
"dataset": {
"type": "kenning.datasets.pet_dataset.PetDataset",
"parameters": {
"dataset_root": "./build/PetDataset",
"image_memory_layout": "NCHW"
}
},
"optimizers": [
{
"type": "kenning.optimizers.nni_pruning.NNIPruningOptimizer",
"parameters": {
"pruner_type": "mean_rank",
"config_list": [
{
"total_sparsity": 0.05,
"op_types": [
"Conv2d",
"Linear"
]
}
],
"training_steps": 16,
"activation": "relu",
"compiled_model_path": "build/nni-pruning-0_05.pth",
"mode": "dependency_aware",
"finetuning_epochs": 3,
"finetuning_batch_size": 64,
"confidence": 8,
"criterion": "torch.nn.CrossEntropyLoss",
"optimizer": "torch.optim.Adam",
"pruning_on_cuda": true,
"finetuning_learning_rate": 0.00005,
"exclude_last_layer": true
}
}
],
"runtime": {
"type": "kenning.runtimes.pytorch.PyTorchRuntime",
"parameters": {
"save_model_path": "./build/nni-pruning-0_05.pth"
}
}
}
Run the above scenario with:
kenning optimize test \
--json-cfg pruning-mobilenetv2-pytorch.json \
--measurements build/nni-pruning.json
To ensure better quality of performance measurements, we suggest running optimization and tests separately, like below:
kenning optimize --json-cfg pruning-mobilenetv2-pytorch.json
kenning test \
--json-cfg pruning-mobilenetv2-pytorch.json \
--measurements build/nni-pruning.json
For more size reduction, you can use larger sparsity with adjusted parameters, like below:
{
"type": "kenning.optimizers.nni_pruning.NNIPruningOptimizer",
"parameters": {
"pruner_type": "mean_rank",
"config_list": [
{
"total_sparsity": 0.15,
"op_types": [
"Conv2d",
"Linear"
]
}
],
"training_steps": 92,
"activation": "relu",
"compiled_model_path": "build/nni-pruning-0_15.pth",
"mode": "dependency_aware",
"finetuning_epochs": 10,
"finetuning_batch_size": 64,
"confidence": 8,
"criterion": "torch.nn.CrossEntropyLoss",
"optimizer": "torch.optim.Adam",
"pruning_on_cuda": true,
"finetuning_learning_rate": 1e-04,
"exclude_last_layer": true
}
}
Results¶
Models can be compared with the generated report:
kenning report \
--measurements \
build/torch.json \
build/nni-pruning.json \
--report-path build/nni-pruning.md \
--to-html
Pruned models have significantly fewer parameters, which results in decreased GPU and VRAM usage without increasing inference time. Summary of a few examples with different sparsity:
Sparsity |
Accuracy |
Number of parameters |
Fine-tuning epochs |
Size reduction |
|---|---|---|---|---|
— |
0.9632653061 |
4,130,853 |
— |
0.00% |
0.05 |
0.9299319728 |
3,660,421 |
3 |
11.27% |
0.15 |
0.8102040816 |
2,813,380 |
10 |
31.61% |
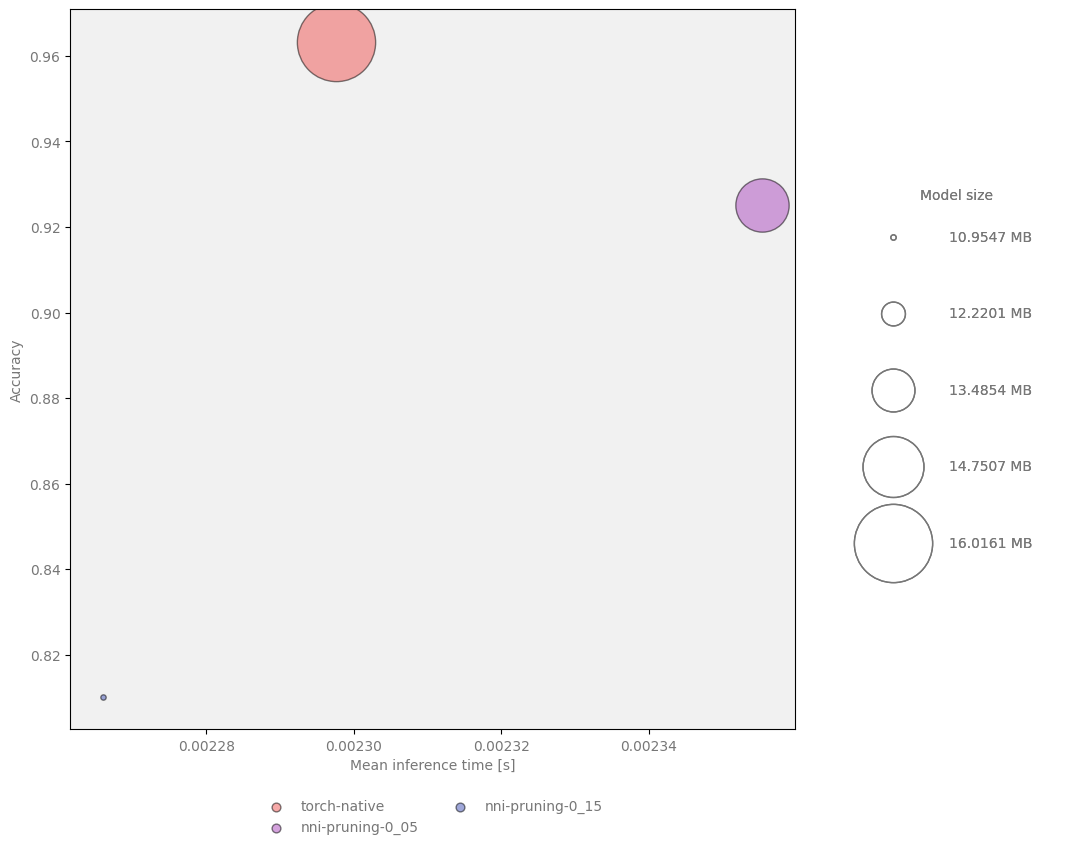
Figure 1 Model size, speed and quality comparison for NNI pruning¶
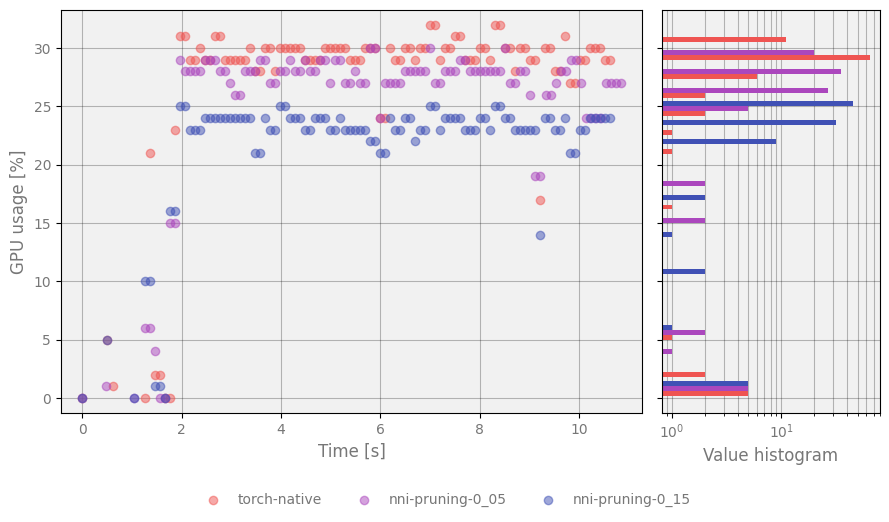
Figure 2 Plot represents changes of GPU usage over time¶
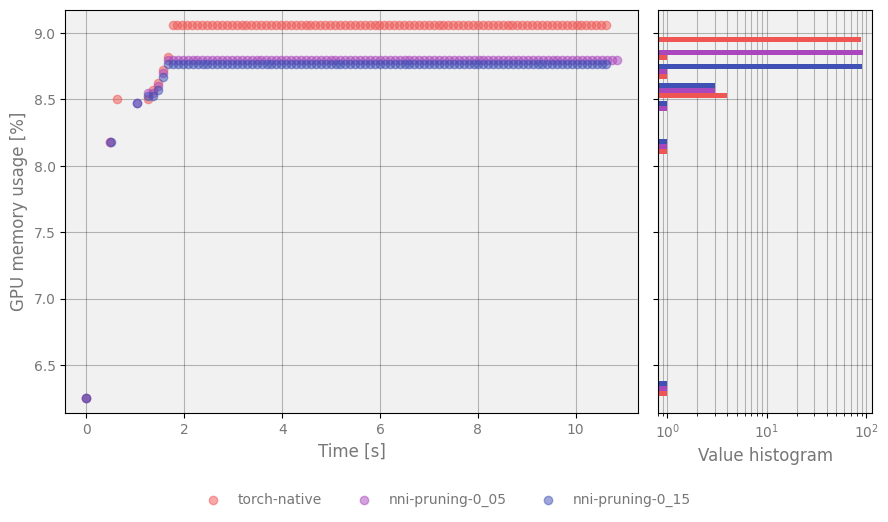
Figure 3 Plot represents changes of GPU RAM usage over time¶