Unstructured Pruning of TensorFlow Models¶
This section contains a tutorial for unstructured pruning of the TensorFlow classification model.
As is the case with most pruning techniques, this type of unstructured pruning requires fine-tuning after “removing” certain connections through training. In unstructured pruning, the weights for certain connections are set to zero. The weights and layers are not removed, but the matrices holding weights become sparse. It can be used to improve model compression (for storage purposes) and for use with dedicated hardware and libraries that can take advantage of sparse computing.
Setup¶
A few additional dependencies are required to prune TensorFlow models, they can be installed using the following command:
pip install "kenning[tensorflow,reports] @ git+https://github.com/antmicro/kenning.git"
Experiments¶
First, we need to know the performance of the original model which can be achieved by running the following pipeline:
{
"model_wrapper": {
"type": "kenning.modelwrappers.classification.tensorflow_pet_dataset.TensorFlowPetDatasetMobileNetV2",
"parameters": {
"model_path": "kenning:///models/classification/tensorflow_pet_dataset_mobilenetv2.h5"
}
},
"dataset": {
"type": "kenning.datasets.pet_dataset.PetDataset",
"parameters": {
"dataset_root": "./build/PetDataset"
}
}
}
To test it, run:
kenning test \
--json-cfg mobilenetv2-tensorflow.json \
--measurements build/tf.json
TensorflowPruningOptimizer has two main parameters for adjusting the pruning process:
target_sparsity- defines sparsity of weights after pruning,prune_dense- iftrue, only dense layers will be pruned instead of the entire model.
You can also adjust how often a model will be pruned (with pruning_frequency), and when it cannot be pruned (pruning_end).
You can also chose an optimizer (one of adam, RMSprop or SGD) and specify if network’s output is normalized with disable_from_logits.
In this example, we decided to fine-tune the model for three epochs with batch size equal to 128.
{
"model_wrapper": {
"type": "kenning.modelwrappers.classification.tensorflow_pet_dataset.TensorFlowPetDatasetMobileNetV2",
"parameters": {
"model_path": "kenning:///models/classification/tensorflow_pet_dataset_mobilenetv2.h5"
}
},
"dataset": {
"type": "kenning.datasets.pet_dataset.PetDataset",
"parameters": {
"dataset_root": "./build/PetDataset"
}
},
"optimizers": [
{
"type": "kenning.optimizers.tensorflow_pruning.TensorFlowPruningOptimizer",
"parameters": {
"compiled_model_path": "./build/tf-pruning-0_15.h5",
"target_sparsity": 0.15,
"batch_size": 128,
"epochs": 3,
"pruning_frequency": 20,
"pruning_end": 120,
"save_to_zip": true
}
}
]
}
To prune the model, run:
kenning optimize \
--json-cfg pruning-mobilenetv2-tensorflow.json
kenning test \
--json-cfg pruning-mobilenetv2-tensorflow.json \
--measurements build/tf-pruning.json
Despite the fact, that the Kenning CLI is capable of running commands in sequence (like kenning optimize test [FLAGS]), we suggest separating them for more measurement precision.
In order to compare a model before and after pruning, you can generate a report using the following command:
kenning report \
--measurements \
build/tf.json \
build/tf-pruning.json \
--report-path build/tf-pruning.md \
--to-html
For greater size reduction, we can use larger sparsity with adjusted parameters, like below:
{
"type": "kenning.optimizers.tensorflow_pruning.TensorFlowPruningOptimizer",
"parameters": {
"compiled_model_path": "./build/tf-pruning-0_3.h5",
"target_sparsity": 0.3,
"batch_size": 128,
"epochs": 5,
"pruning_frequency": 40,
"pruning_end": 82,
"save_to_zip": true
}
}
The default TensorFlow version of the pretrained MobileNetV2 (kenning:///models/classification/tensorflow_pet_dataset_mobilenetv2.h5) is exported with an optimizer, resulting in size increase.
To ensure better measurement quality, we will present the data with the default MobileNetV2 stripped from any unnecessary information.
Summary of pruned models:
Sparsity |
Accuracy |
Compressed size |
Size reduction |
|---|---|---|---|
— |
0.9605442177 |
15,508,373 |
0.00% |
0.15 |
0.9190476190 |
14,062,345 |
9.32% |
0.3 |
0.8367346939 |
12,349,076 |
20.37% |
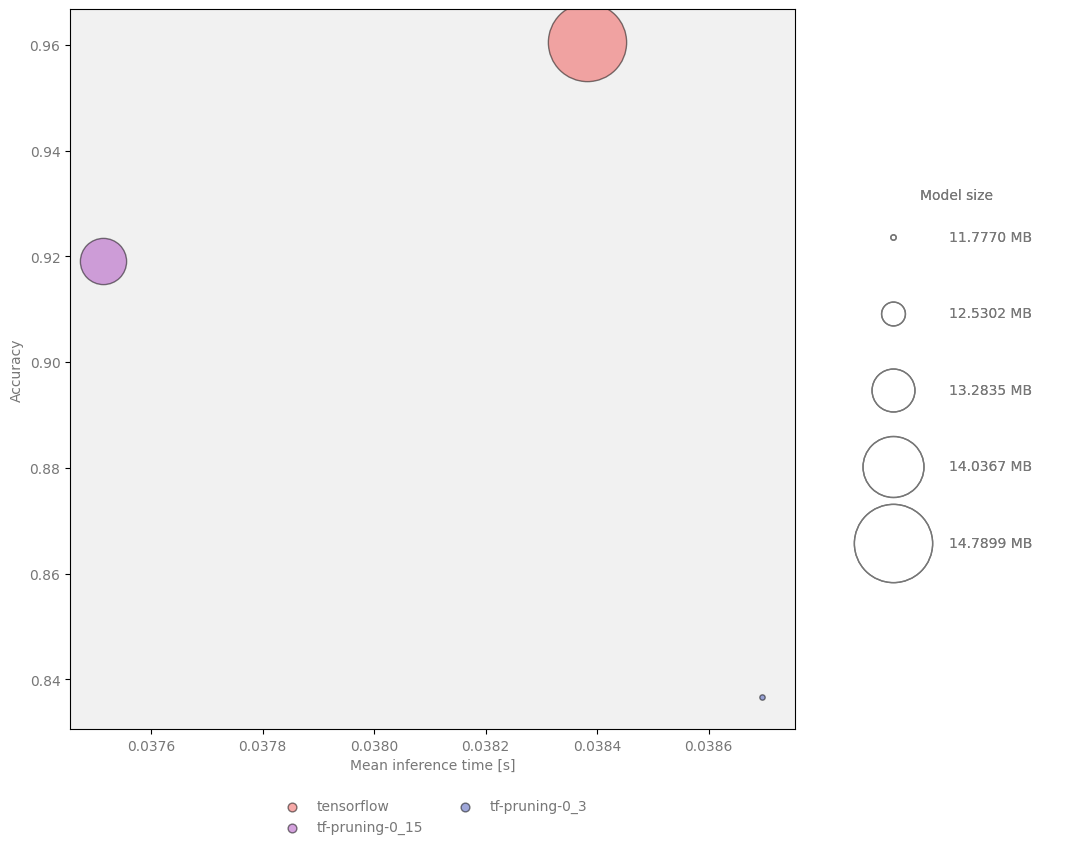
Figure 4 Model size, speed and quality comparison for TensorFlow pruning¶
(Optional) Clustering¶
Kenning provides a few other methods for reducing the size of the model. One of such techniques is clustering. It groups weights into K groups of similar values. Then, it computes K centroids based on those weights and use them as values for new weights. In weight matrices, we store indices to corresponding centroid instead of values. The indices can be stored as integers with a very small number of bits necessary to represent them, reducing the model size significantly.
You can do this by adding kenning.optimizers.tensorflow_clustering.TensorFlowClusteringOptimizer:
"optimizers": [
{
"type": "kenning.optimizers.tensorflow_pruning.TensorFlowPruningOptimizer",
"parameters": {
"compiled_model_path": "./build/tf-pruning-0_15.h5",
"target_sparsity": 0.15,
"batch_size": 128,
"epochs": 5,
"pruning_frequency": 10
}
},
{
"type": "kenning.optimizers.tensorflow_clustering.TensorFlowClusteringOptimizer",
"parameters": {
"compiled_model_path": "./build/tf-pruning-clustering.h5",
"cluster_dense": false,
"preserve_sparsity": true,
"clusters_number": 60
}
}
]
To run it, use:
kenning optimize test report \
--json-cfg pruning-clustering-mobilenetv2-tensorflow.json \
--measurements build/tf-all.json \
--report-path build/tf-pruning-clustering.md \
--to-html
Clustering allows for substantial model size reduction without significant decrease in quality. Here is a comparison of a model with and without clustering:
Sparsity |
Number of clusters |
Accuracy |
Compressed size |
Size reduction |
|---|---|---|---|---|
— |
— |
0.9605442177 |
15,508,373 |
0.00% |
0.15 |
— |
0.9190476190 |
14,062,345 |
9.32% |
0.15 |
60 |
0.9006802721 |
4,451,142 |
71.30% |
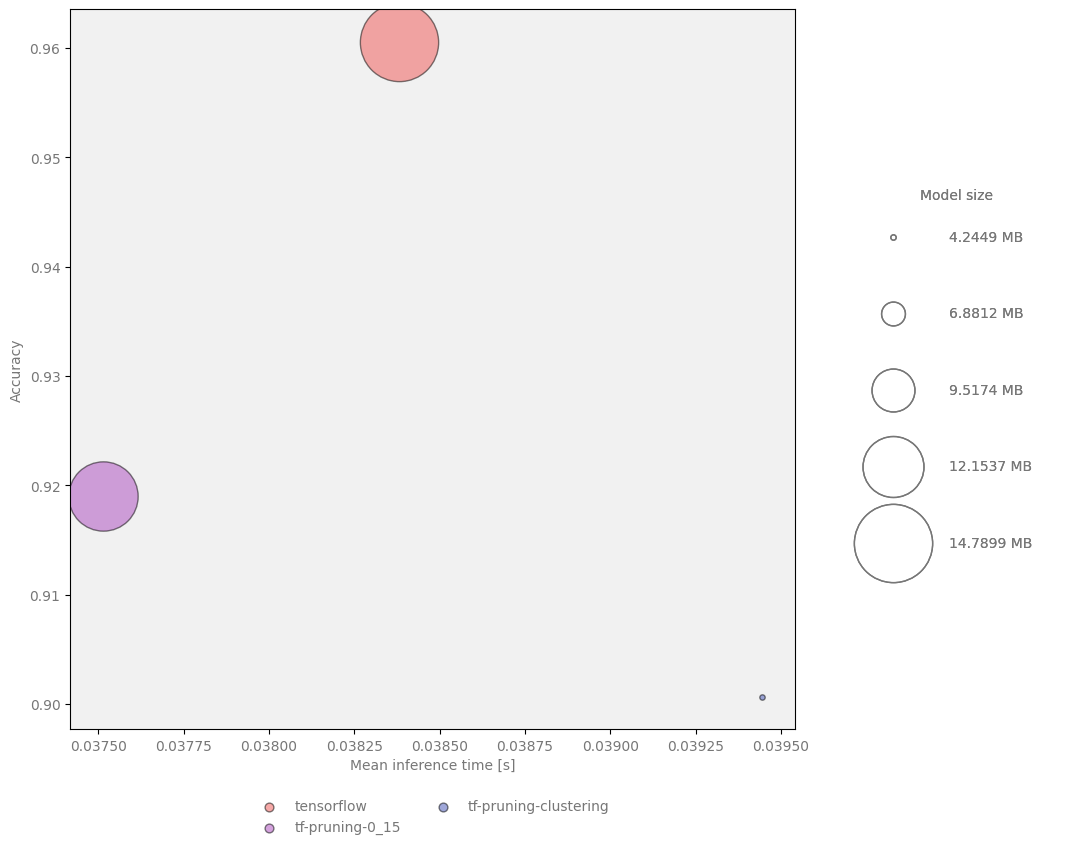
Figure 5 Model size, speed and quality comparison for TensorFlow pruning and clustering¶