Model quantization and compilation using TFLite and TVM¶
Let’s consider a simple scenario where we want to optimize the inference time and memory usage of a classification model executed on a x86 CPU.
To do this, we are going to use the PetDataset Dataset and the TensorFlowPetDatasetMobileNetV2 ModelWrapper.
Prepare environment¶
First of all, we need to install all necessary dependencies:
pip install "kenning[tensorflow,tflite,tvm,reports] @ git+https://github.com/antmicro/kenning.git"
Train the model (optional)¶
We will skip the training process, we will use tensorflow_pet_dataset_mobilenetv2.h5.
In Kenning, available models and resources can be downloaded using URIs with the kenning:// scheme, in this case kenning:///models/classification/tensorflow_pet_dataset_mobilenetv2.h5.
The training of the above model can be performed using the following command:
kenning train \
--modelwrapper-cls kenning.modelwrappers.classification.tensorflow_pet_dataset.TensorFlowPetDatasetMobileNetV2 \
--dataset-cls kenning.datasets.pet_dataset.PetDataset \
--logdir build/logs \
--dataset-root build/pet-dataset \
--model-path build/trained-model.h5 \
--batch-size 32 \
--learning-rate 0.0001 \
--num-epochs 50
Benchmarking a model using a native framework¶
First, we want to check how the trained model performs using the native framework on CPU.
For this, we will use the kenning test tool.
The tool is configured with JSON files (scenarios).
In our case, the JSON file (named native.json) will look like this:
{
"model_wrapper": {
"type": "kenning.modelwrappers.classification.tensorflow_pet_dataset.TensorFlowPetDatasetMobileNetV2",
"parameters": {
"model_name": "native",
"model_path": "kenning:///models/classification/tensorflow_pet_dataset_mobilenetv2.h5",
"batch_size": 32,
"learning_rate": 0.0001,
"num_epochs": 50,
"logdir": "build/logs"
}
},
"dataset": {
"type": "kenning.datasets.pet_dataset.PetDataset",
"parameters": {
"dataset_root": "./build/PetDataset"
}
}
}
This JSON provides a configuration for running the model natively and evaluating it against a defined Dataset.
For every class in the JSON file above, two keys are required: type which is a module path of our class and parameters which is used to provide arguments used to create instances of our classes.
In model_wrapper, we specify the model used for evaluation - here it is MobileNetV2 trained on PetDataset.
The model_path is the path to the saved model.
The TensorFlowPetDatasetMobileNetV2 model wrapper provides methods for loading the model, preprocessing the inputs, postprocessing the outputs and running inference using the native framework (TensorFlow in this case).
The dataset provided for evaluation is PetDataset - here we specify that we want to download the dataset to the ./build/pet-dataset directory (dataset_root).
The PetDataset class can download the dataset (if necessary), load it, read the inputs and outputs from files, process them, and implement evaluation methods for the model.
With the config above saved in the native.json file, run the kenning test scenario:
kenning test \
--json-cfg mobilenetv2-tensorflow-native.json \
--measurements build/native.json
This tool runs inference based on the given configuration, evaluates the model and stores quality and performance metrics in JSON format, saved to the build/native.json file.
All other JSONs in this example use case can be executed with this command.
To visualize the evaluation and benchmark results, run the kenning report tool:
kenning report \
--report-path build/benchmarks/native.md \
--measurements build/native.json \
--root-dir build/benchmarks \
--img-dir build/benchmarks/img \
--report-types performance classification \
--report-name 'native'
The kenning report tool takes the output JSON file generated by the kenning test tool, and creates a report titled native, which is saved in the build/benchmarks/native.md directory.
As specified in the --report-types flag, we create performance and classification metrics sections in the report (for example, there is also a detection report type for object detection tasks).
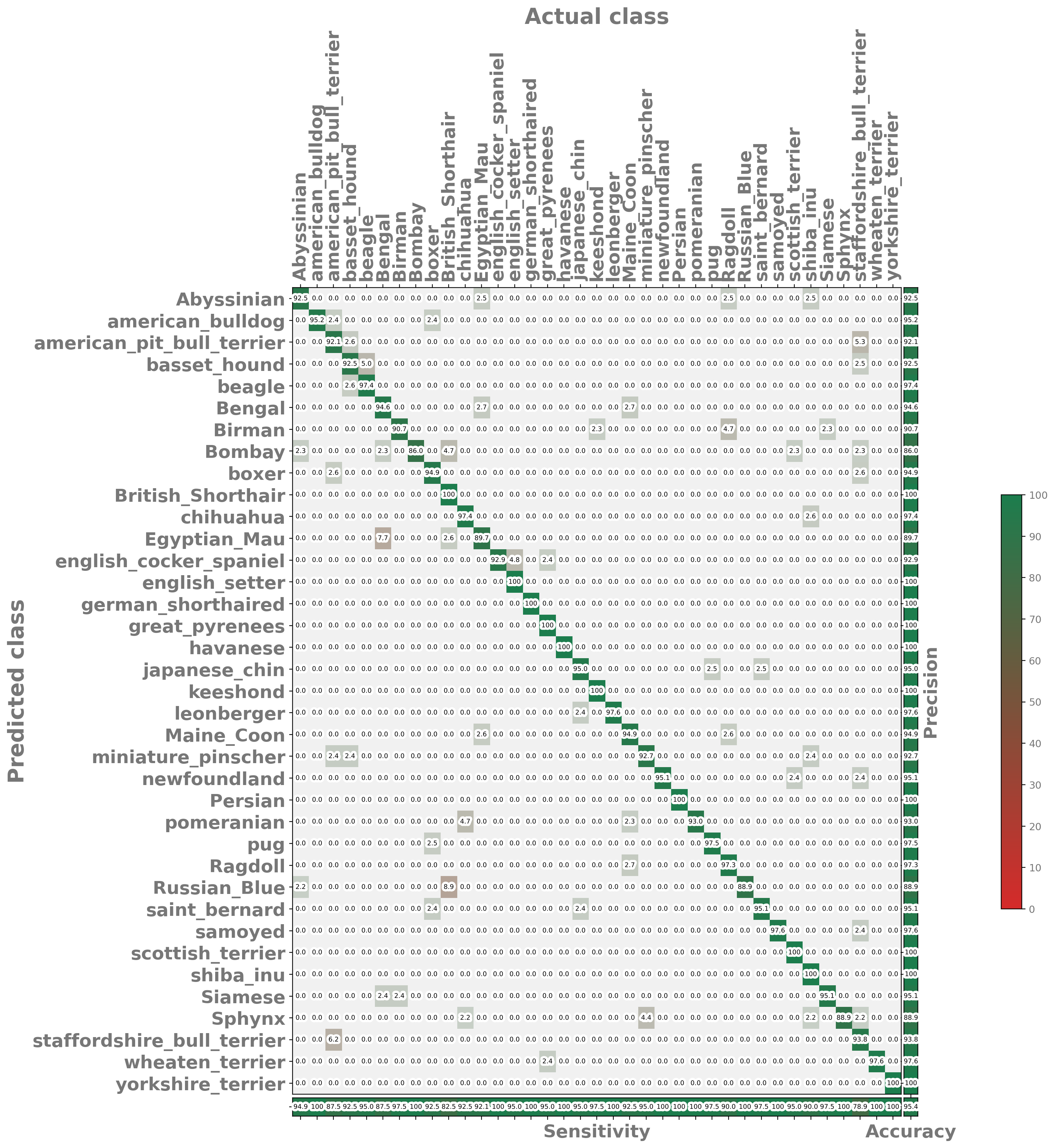
The build/benchmarks/img directory contains images with the native_* prefix visualizing the confusion matrix, CPU and memory usage, as well as inference time.
The build/benchmarks/native.md file is a Markdown document containing a full report for the model.
The document links to the generated visualizations and provides aggregated information about CPU and memory usage, as well as classification quality metrics, such as accuracy, sensitivity, precision, or G-Mean.
Such a file can be included in a larger, Sphinx-based documentation, which allows easy, automated report generation, using e.g. CI, like in the case of the Kenning documentation.
We can also use a simplified command:
kenning report \
--report-path build/benchmarks/native.md \
--measurements build/native.json
The available --report-types will be derived from measurements in the build/native.json file.
Conveniently, kenning test and kenning report commands can be reduced to a single kenning run:
kenning test report \
--json-cfg mobilenetv2-tensorflow-native.json \
--measurements build/native.json \
--report-path build/benchmarks/native.md
While native frameworks are great for training and inference, model design, training on GPUs and distributing training across many devices, e.g. in a cloud environment, there is a fairly large variety of inference-focused frameworks for production purposes that focus on getting the most out of hardware in order to get results as fast as possible.
Optimizing a model using TensorFlow Lite¶
TensorFlow Lite is one of such frameworks. It is a lightweight library for inferring networks on edge - it has a small binary size (which can be reduced further by disabling unused operators) and a highly optimized format of input models, called FlatBuffers.
Before the TensorFlow Lite Interpreter (runtime for the TensorFlow Lite library) can be used, the model first needs to be optimized and compiled to the .tflite format.
Let’s add a TensorFlow Lite Optimizer that will convert our MobileNetV2 model to a FlatBuffer format, as well as a TensorFlow Lite Runtime that will execute the model:
"optimizers": [
{
"type": "kenning.optimizers.tflite.TFLiteCompiler",
"parameters": {
"target": "default",
"compiled_model_path": "./build/fp32.tflite",
"inference_input_type": "float32",
"inference_output_type": "float32"
}
}
The configuration of the already existing blocks does not change, and the dataset will not be downloaded again since the files are already present.
The first new addition in comparison to the previous flow is the presence of the optimizers list, which allows us to add one or more objects inheriting from the kenning.core.optimizer.Optimizer class.
Optimizers read the model from the input file, apply various optimizations, and then save the optimized model to a new file.
In our current scenario, we will use the TFLiteCompiler class - it reads the model in a Keras-specific format, optimizes the model and saves it to the ./build/fp32.tflite file.
The parameters of this particular Optimizer are worth noting here (each Optimizer usually has a different set of parameters):
target- indicates what the desired target device (or model type) is, regular CPU isdefault. Another example here could beedgetpu, which can compile models for the Google Coral platform.compiled_model_path- indicates where the model should be saved.inference_input_typeandinference_output_type- indicate what the input and output type of the model should be. Usually, all trained models use FP32 weights (32-bit floating point) and activations - usingfloat32here keeps the weights unchanged.
Another addition is the runtime block which provides a class inheriting from the kenning.core.runtime.Runtime class that is able to load the final model and run inference on target hardware.
Usually, each Optimizer has a corresponding Runtime capable of running its results.
To compile the scenario (called tflite-fp32.json), run:
kenning optimize test report \
--json-cfg mobilenetv2-tensorflow-tflite-f32.json \
--measurements build/tflite-fp32.json \
--report-path build/benchmarks/tflite-fp32.md
While it depends on the platform used, you should be able to see a significant improvement in both inference time (model ca. 10-15x faster model compared to the native model) and memory usage (output model ca. 2x smaller). What’s worth noting is that we get a significant improvement with no harm to the quality of the model - the outputs stay the same.
Quantizing a model using TensorFlow Lite¶
To further reduce memory usage, we can quantize the model - it is a process where all weights and activations in a model are calibrated to work with low-precision floating-point or integer reporesentations (i.e. INT8), instead of the FP32 precision.
While it may severely harm prediction quality, the quality reduction can be negligible with proper calibration.
The model can be quantized during the compilation process in TensorFlow Lite. With Kenning, it can be achieved with the following simple additions:
"optimizers": [
{
"type": "kenning.optimizers.tflite.TFLiteCompiler",
"parameters": {
"target": "int8",
"compiled_model_path": "./build/int8.tflite",
"inference_input_type": "int8",
"inference_output_type": "int8"
}
}
The only changes here in comparison to the previous configuration appear in the TFLiteCompiler configuration. We change target, inference_input_type and inference_output_type to int8.
Then, in the background, TFLiteCompiler fetches a subset of images from the PetDataset object to calibrate the model and the entire model calibration process happens automatically.
Let’s run the scenario above (tflite-int8.json):
kenning optimize test report \
--json-cfg mobilenetv2-tensorflow-tflite-int8.json \
--measurements build/tflite-int8.json \
--report-path build/benchmarks/tflite-int8.md
This results in a model over 7 times smaller compared to the native model without significant loss of accuracy (but without speed improvement).
Speeding up inference with Apache TVM¶
To speed up inference of a quantized model, we can utilize vector extensions in x86 CPUs, more specifically AVX2. To do this, we can use the Apache TVM framework to compile efficient runtimes for various hardware platforms. The scenario looks like this:
"optimizers": [
{
"type": "kenning.optimizers.tflite.TFLiteCompiler",
"parameters": {
"target": "int8",
"compiled_model_path": "./build/int8.tflite",
"inference_input_type": "int8",
"inference_output_type": "int8"
}
},
{
"type": "kenning.optimizers.tvm.TVMCompiler",
"parameters": {
"target": "llvm -mcpu=core-avx2",
"opt_level": 3,
"conv2d_data_layout": "NCHW",
"compiled_model_path": "./build/int8_tvm.tar"
}
}
As visible, adding a new framework is just a matter of simply adding and configuring another optimizer and using a Runtime corresponding to the final Optimizer.
The TVMCompiler, with llvm -mcpu=core-avx2 as the target, optimizes and compiles the model to use vector extensions.
The final result is a .tar file containing a shared library that implements the entire model.
Let’s compile the scenario (tvm-avx2-int8.json):
kenning optimize test report \
--json-cfg mobilenetv2-tensorflow-tvm-avx-int8.json \
--measurements build/tvm-avx2-int8.json \
--report-path build/benchmarks/tvm-avx2-int8.md
This results in a model over 40 times faster compared to the native implementation, with a 3x reduction in size.
This demonstrates how easily we can interconnect various frameworks and get the most out of hardware using Kenning, while performing just minor alterations to the configuration file.
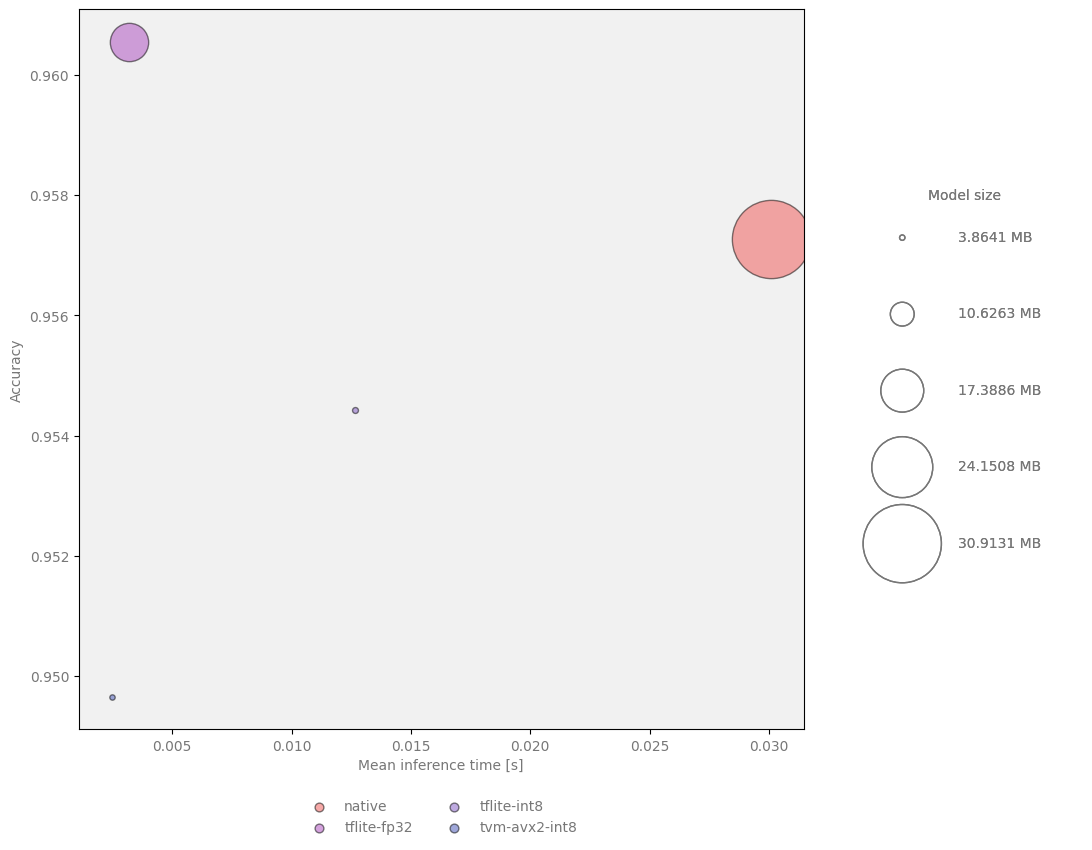
The summary of passes looks as follows:
Speed boost |
Accuracy |
Size reduction |
|
|---|---|---|---|
native |
1 |
0.9572730984 |
1 |
tflite-fp32 |
15.79405698 |
0.9572730984 |
1.965973551 |
tflite-int8 |
1.683232669 |
0.9519662539 |
7.02033412 |
tvm-avx2-int8 |
41.61514549 |
0.9487005035 |
3.229375069 |
Automated model comparison¶
The kenning report tool also allows us to compare evaluation results for multiple models.
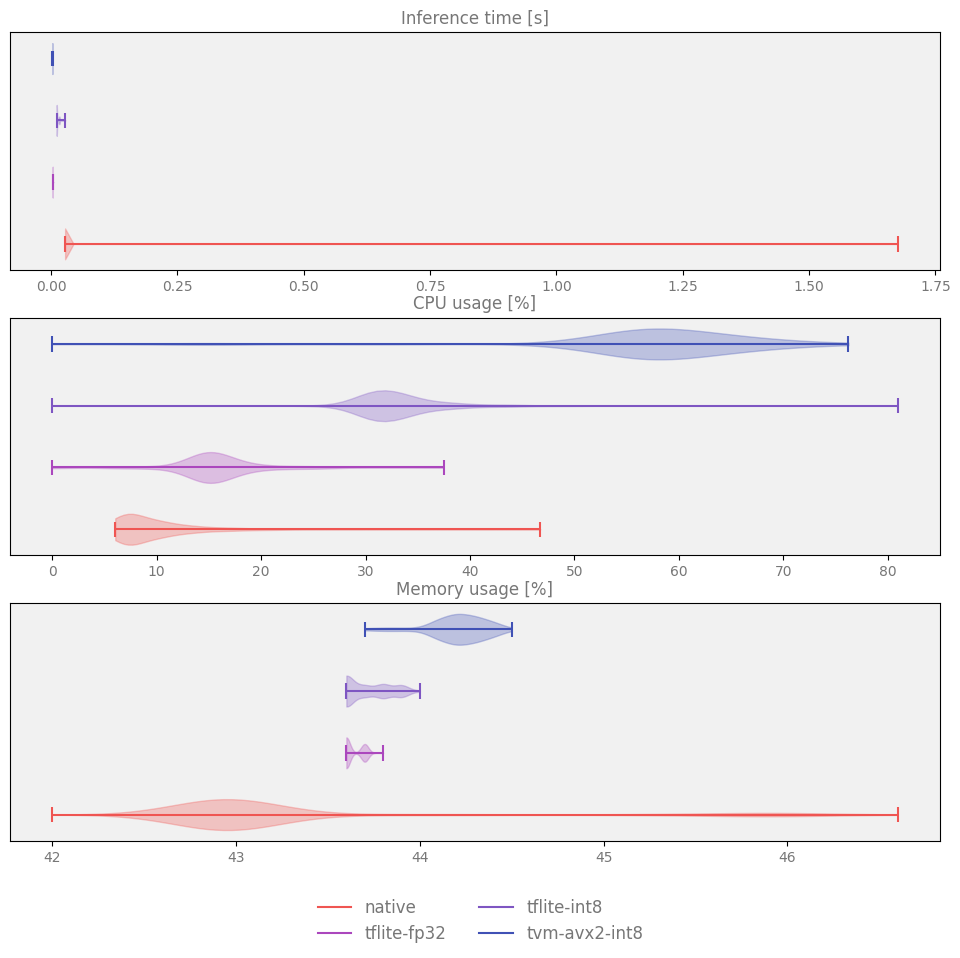
Apart from creating a model summary table, it also creates plots aggregating measurements collected during the evaluation process.
To create a comparison report for the above experiments, run:
kenning report \
--report-path build/benchmarks/summary.md \
--measurements \
build/native.json \
build/tflite-fp32.json \
build/tflite-int8.json \
build/tvm-avx2-int8.json
Some examples of comparisons between various models rendered with the script:
Accuracy, inference time and model size comparison:
Resource utilization distribution:
Comparison of classification metrics:
And more